
2024. 8. 22.ㆍTech
안녕하세요! 케이뱅크 경영테크팀 김우성 입니다.
이번 주제는 경영테크팀에서 운영 중인 '금융거래정보제공 시스템(FID)' 에 대한 소개와
더 나은 시스템으로 발돋움하기 위해 MySQL에서 SingleStore 로의 전환과정을 공유하고자 합니다.
1. 금융거래정보제공?
2. 금융거래정보제공시스템(FID)과 DBMS 전환배경
3. SingleStore DBMS의 특징
4. 결과 & ISSUE 사항
5. 마무리하며
지금 시작합니다!
금융거래정보제공?
시스템 소개 전 업무에 대해 간단히 소개드리겠습니다.
금융거래정보제공은 '금융실명거래 및 비밀보장에 관한 법률 제4조'에 근거하여 정보제공요구자가 법률 요건에 맞게 요청을 하는 경우 사용목적에 맞게 금융정보를 제공하고 이에 대해 명의인에게 거래정보제공사실을 통보하는 금융회사에 필수적인 업무입니다.
금융거래정보제공 업무는 크게 2가지로 나뉩니다.
- 요청
정보제공요구자(정부, 경찰, 국세청 등의 기관)가 특정 명의인에 대해 금융거래정보를 요청하면 이를 접수받아 법에서 허용하는 범위의 금융정보를 제공합니다.
- 통보
정보가 제공된 명의인에게 정보가 제공되었음을 통보(거래정보 등의 제공사실 통보)하는 과정입니다.
또한 업무의 단계는 간략히 3단계로 요약할 수 있습니다.
1. 정보제공요구자가 금융정보를 은행에 요청한다.
2. 은행은 금융정보를 요구자에게 제공한다.
3. 정보가 제공된 명의인에게 '정보를 제공했다'는 사실을 알리기 위해 통보한다.

이런 업무를 더 효율적으로 처리하기 위해 케이뱅크는 사내 '금융거래정보제공시스템(FID)'을 통해 업무를 지원하고 있습니다.
금융거래정보제공시스템(FID)과 DBMS 전환배경
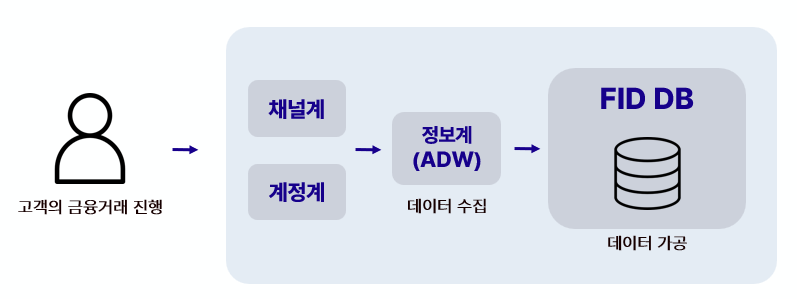
'금융거래정보제공시스템(Financial Information Delivery, 이하 FID)'의 구조와 데이터 흐름의 특징을 소개해드리겠습니다.
제공해야 하는 금융정보는 단순한 정보조회성 조회를 포함하여 복잡한 조건이 추가된 조회, 그리고 수천만의 대용량 일괄조회 등 다양한 조건과 방식으로 요구를 처리하고 있습니다.
이와 같이 다양한 정보를 요청하는 업무 특성상 FID에서는 당행에서 발생하는 금융정보 Data를 일배치를 통해 가공하여 적재하고 있습니다. Data 관점에서 시스템의 대표적인 특징을 아래와 같이 정리해 볼 수 있습니다.
1. 대용량 데이터를 Bulk Load 하고 이를 가공하는 SQL문이 매일 발생한다.
2. 1회 요청에 수천만명의 고객 금융정보를 추출하는 대용량 데이터 추출이 많다.
3. 다양한 테이블을 JOIN 하여 집계, 분석하는 SQL Query가 많다.
케이뱅크는 처음 거래를 시작한 2017년부터 지금까지 약 8년간 운영 데이터가 지속적으로 쌓여왔습니다.
특히 21년도부터는 고객수가 급격히 늘어나며 그에 따라 거래량 또한 많이 늘어나게 되었습니다.
FID시스템의 Data 양이 기하급수적으로 늘어나면서 동일한 SQL 명령어를 수행하더라도 절대적인 Data Scan양이 증가하여 성능저하가 불가피하였습니다.
SQL Tuning, Index 추가, Scale-Up 등 다방면으로 개선해 봤지만 전통적인 RDBMS의 구조적인 한계가 있었고 날이 갈수록 늘어나는 Data의 양은 스토리지 비용증가로 이어지고 있었습니다.
이런 이슈를 해결하고자 내부적으로 논의한 끝에 신규 DBMS로의 전환을 결정하게 되었고 'OLTP/OLAP 모두를 준수한 성능을 발휘할 수 있는 DBMS, 스토리지를 효율적으로 사용할 수 있는 DBMS' 라는 목적을 설정해 리서치를 진행하였습니다. 그 결과, 다양한 비교군 중에서 최종적으로 SingleStore DB를 선택하게 되었습니다.
SingleStore DB를 선택한 이유로 크게 3가지 장점이 있었고 이 장점은 현재 금융거래제공시스템이 안고 있는 문제점을 충분히 커버할 수 있을 것이라 판단했습니다.
SingleStore DBMS의 특징
1. 분산 아키텍처
SingleStore DB의 대표적인 특징은 분산 아키텍처입니다.
Aggregator Node, Leaf Node라는 개념으로 소개하고 있는데 다음과 같은 기능을 담당합니다.

| Aggregator Node | Leaf Node | |
| 역할/특성 |
• SQL 쿼리를 수신해 Leaf Node로 라우팅
• 각 Leaf Node가 처리한 쿼리 결과를 취합/집계 후 회신
|
• 데이터를 저장하는 스토리지
• 샤딩을 통해 데이터 각 Partition 영역에 고르게 분배저장 • 여러 파티션을 통한 쿼리의 병렬 처리 담당
• ColumnStore 사용 시 고압축 & 빠른 집계 가능
|
이와 같은 구조로 실제 애플리케이션에서 DB로 요청을 한 경우 아래와 같은 방식으로 집계 테이블도 빠르게 조회할 수 있는 특징을 가집니다.
1. Aggregator Node가 SQL 문을 접수
2. 실행계획에 맞게 필요한 Leaf Node에 분산하여 병렬로 작업수행
3. 각 Leaf별 조회된 데이터를 Aggregator Node가 취합하여 애플리케이션으로 전달
2. 유연한 Scale-Out
Singlestore DB는 Node를 추가하는 방식으로 Scale-Out을 진행합니다.
- 사용자가 많아 트랜젝션의 수 자체가 많은 경우 : Aggregator Node 확장
- 트랜젝션의 양은 적으나 대용량 추출, 집계성 조회 등 분석용 SQL이 많은 경우 : Leaf Node 확장
상황에 따라 필요한 Node를 추가하여 업무특성에 맞게 조절할 수 있는 유연한 확장 아키텍처를 가지고 있습니다.
3. RowStore, ColumnStore 모두 지원하는 하이브리드 저장방식
전통적으로 레코드를 기반으로 저장하는 RowStore 뿐만 아닌 Column단위로 저장하는 ColumnStore 또한 지원하고 있습니다.
Rowstore과 다르게 컬럼단위로 저장하면 반복되거나 유사한 데이터가 많아 이에 대한 압축률이 높고 디스크를 주 저장공간으로 사용하기 때문에 대용량 데이터를 처리함에 있어 비용적으로 유리한 특징이 있습니다.
SingleStore에서는 Sort Key를 기준으로 데이터를 정렬하여 컬럼단위로 저장하고 있습니다. 그 결과, 각 파티션 영역별로 균일한 양이 저장되고 select 시 필요한 영역만 범위 Scan하여 모수가 줄어들어 비교적으로 SQL 성능에 유리할 수 있도록 설계되어 있습니다.
대용량 OLAP성 조회가 90%이상인 FID시스템에서는 ColumnStore Table을 적극적으로 사용해 설계하였습니다.
이러한 하이브리드 저장방식은 시스템에 맞는 워크로드 유형을 파악하여 테이블 설계 시 저장방식을 선택할 수 있어 OLTP/OLAP 모두 유연하게 대처 할 수 있는 특징을 가집니다.
** 각 파티션 영역별 Data 저장 시 Sort Key값 설정에 따라 균일하지 않을 수도 있어 초기 설계 시 설정을 잘해야 합니다.
MySQL vs. SingleStore
이를 바탕으로 현재 DBMS와 비교해 보았습니다.
| MySQL (5.7.*) | MySQL (8.0.*) | SingleStore (8.5.*) | |
| DB특성 | RDBMS | RDBMS | RDBMS |
| 지원 Join | - NL Join 지원 - Hash Join 미지원 > 대용량 처리 및 집계 SQL에 불리. OLTP 에 특화 |
- NL Join 지원 - Hash Join 지원 |
- NL Join 지원 - Hash Join 지원 |
| 분석기능 | 기본적인 분석함수 지원 | 개선된 분석함수 지원 | 기본 분석함수 및 OLAP 기능 제공 |
| 분산처리 | 단일 노드 분산처리는 추가 솔루션 필요 |
단일 노드 분산처리는 추가 솔루션 필요 |
기본적인 분산 처리 및 클러스터링 지원 |
| 스케일링 방식 | 수직적 스케일링 | 수직적 스케일링 | 수평적 스케일링 (클러스터링) |
| 스토리지 저장방식 | InnoDB 스토리지 엔진 | 개선된 InnoDB 압축기능으로 더 나은 성능 제공 | ColumnStore 방식 저장으로 효과적인 압축 가능 RowStore 방식 또한 지원 |
| Syntax | - | - | MySQL 호환 |
비교표를 토대로 각 성능은 아래와 같이 비교해 볼 수 있었습니다.
OLAP 적합성 : MySQL (5.7.*) < MySQL(8.0.*) =< SingleStore(8.5.*)
스케일링 방식 : MySQL (5.7.*) < MySQL(8.0.*) < SingleStore(8.5.*)
스토리지 압축률 : MySQL (5.7.*) < MySQL(8.0.*) << SingleStore(8.5.*)
위와 같은 결과를 통해 '금융거래정보제공시스템'의 업무특성에 따라 Singlestore DB가 적합하다 판단했으며 이를 검증하기 위한 PoC를 진행하게 되었습니다.
PoC 결과 & ISSUE 사항
이번 본 전환을 위해 PoC에서는 아래와 같은 목표를 가지고 진행했습니다.
- 빠른 집계 : OLAP성 SQL Query에 대한 빠른 집계가 가능할 것
- BATCH 적재 : 대용량 적재를 위한 Load Data의 성능이 현재와 같거나 더 좋은 성능을 발휘할 것
- 최소한의 공수 : DB전환으로 인한 Query Tuning 공수가 적을 것
테스트 환경은 기존 운영서버환경을 Clone 하여 스펙을 동일하게 맞추었고 Data 또한 동일하게 이관하여 진행하였습니다.
그 결과, 3가지의 유의미한 결과를 도출할 수 있었습니다.
Goal 1. 빠른 집계 - Slow Query 비교
(단위 : 초)
| 작업유형 | MySQL (5.7.x) | SingleStore (8.5.x) | |
| A Query | 30만 건 이상 7개 테이블의 LEFT JOIN Select |
8.932 | 1.938 |
| B Query | 대용량 테이블 중 일부 Delete | 40.200 | 0.021 |
| C Query | 고객 100만명 이상 거래기간 년단위 이상 범위 Scan 조회 5개 테이블 LEFT Join Select |
14.084 | 5.01 |
Goal 2. BATCH 적재 - 대량 Load Data 비교
조건은 다음과 같습니다. 컬럼 건수 : 89건 / 레코드 건수 : 16,602,556건 / INFILE 방식
(단위 : 초)
| 회차 | 1 | 2 | 3 | 4 | 5 | ... | 평균 |
| MySQL (5.7.x) | 3,483 | 3,698 | 3,301 | 3,250 | 3,088 | ... | 3,391 |
| SingleStore (8.5.x) | 367 | 361 | 332 | 356 | 350 | ... | 345 |
Slow Query 외에도 99% 이상의 쿼리문의 속도가 전체적으로 개선되었고 최소 3배 이상의 차이를 얻을 수 있었습니다.
또한 Load Data 테스트에서도 평균 9배의 퍼포먼스 향상을 확인할 수 있었습니다.
이렇게 큰 차이의 퍼포먼스를 발생할 수 있었는지 분석해 봤을 때 여러 장점 중
아래 세 가지가 속도를 개선하는데 가장 큰 영향을 준 것으로 확인됩니다.
- Hash Join 지원
- Aggregator/Leaf Node를 통한 분산처리
- ColumnStore 방식 저장/Sharding을 통한 Scan 조회대상 모수 축소
Goal 3. 최소한의 공수 : 기존 SQL 수용여부 점검 (단일 테이블 select 등 단순 쿼리 제외)
마지막으로 MySQL에서 SingleStore로의 전환 공수를 줄이기 위해 SQL 호환여부를 확인하였습니다.
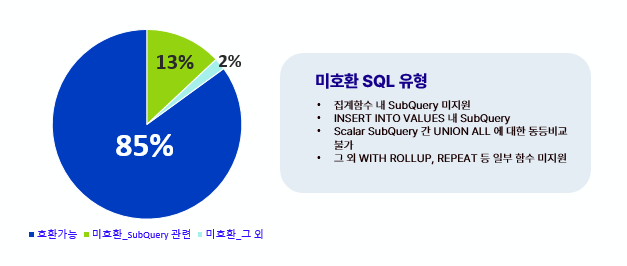
그림과 같이 시스템 내 단순쿼리(단건 테이블 조회 등)를 제외한 SQL Query 232개 중 85%는 즉시 호환이 가능하였습니다. 호환되지 않는 쿼리 13% 는 서브쿼리와 관련 된 ISSUE 였으며 이는 이번 PoC에서 주로 신경 썼어야 하는 부분이었습니다.
SingleStore는 분산 DBMS의 특성상 Data 가 각 Node 별로 분산되어 저장되어 있어 구조적으로 서브쿼리 사용에 제한이 있었는데요. 그러나 Left Join, Exists 등 Tuning을 통해 SQL 상황에 따라 다른 방식으로 대응 가능한 영역이었습니다. 다만 앞으로 운영시 기존 대표적인 DBMS인 MySQL SQL문에 익숙한 개발자라면, 더 유의하여 SQL문을 작성할 필요는 있을 것 같습니다.
결론적으로 SQL 대부분이 즉시 사용이 가능했으며 호환되지 않는 SQL문은 Tuning으로 충분히 쉽게 변경할 수 있어 크게 영향을 미치는 정도는 아니라고 판단하였습니다.
마무리하며
PoC에서 도출한 결과를 바탕으로 이관해도 괜찮다는 결정을 하게 되어 본전환을 진행했고 성공적으로 이관을 완료하여 현재는 시스템을 운영하며 안정적으로 서비스를 운영하고 있습니다
PoC에서 기대한 값과 동일하게 최종 결과물인 운영환경에서도 배치 Bulk Load, DML 수행 속도 모두 이전 대비 훨씬 좋은 성능을 보이고 있습니다. 현업과 IT담당자 모두 업무수행 속도가 많이 개선됨을 체감하고 있습니다
도입 당시, 구조상 불가능한 일부 서브쿼리로 인해 불가피하게 수정할 부분이 있었으나 위에서 언급한 바와 같이 다른 SQL문으로 적용하여 운영 중에 있습니다.
개인적으로 이번 전환을 직접 담당하면서 DBMS가 흔히 알고 있는 것 외에도 다양하다고 인지하고 있었으나 접할 기회가 없었는데 새로운 DBMS도 접할 수 있는 좋은 경험이 되었습니다.
이상으로 글을 마무리하며 또 좋은 글로 공유드릴 수 있었으면 좋겠습니다! 감사합니다.
참고
싱글스토어 공식 홈 : https://www.singlestore.com/
SingleStore | The Real-Time Data Platform for Intelligent Applications
Designed for applications, analytics and AI, SingleStore is the world's only real-time data platform to read, write and reason on petabyte-scale data in a few milliseconds.
www.singlestore.com
에이플랫폼 (싱글스토어 국내 총판) ::https://www.a-platform.biz/
에이플랫폼
서울특별시 영등포구 영신로 166, 304~6호 (영등포반도아이비밸리) TEL : 02 - 706 -9912 FAX : 0505 - 991 - 9911 EMAIL : info@a-platform.biz Copyright A Platform Inc. All rights reserved.
www.a-platform.biz
'Tech' 카테고리의 다른 글
| 아이콘이 아이콘을 낳는다?_케이뱅크 아이콘 AI 연습기 1편 (2) | 2024.12.20 |
|---|---|
| aws re:Invent 2024 참가자를 위한 (뒤늦은) 2023 참관기/팁 방출 (20) | 2024.10.08 |
| 거대 언어 모델 튜닝을 위한 미니멀리스트 접근법: 2부 - QLoRA로 학습하기 (3) | 2024.05.21 |
| 거대 언어 모델 튜닝을 위한 미니멀리스트 접근법: 1부 - PEFT 알아보기 (1) | 2024.04.29 |
| 옵시디언(obsidian) : 나만의 두번째 뇌(Second Brain) 구축하기 (1) | 2024.04.11 |