
2025. 6. 21.ㆍTech

안녕하세요.
케이뱅크 데이터인텔리전스팀에서 Data Scientist로 일하고 있는 조용걸입니다.
이전에 LLM을 이용한 여행 컨시어지 만들기 link
기고글을 통해서 행내 IT 동아리 Edit 활동을 소개드린 적이 있는데요.
2025년 2분기 세미나 발표를 요청 받아서 어떤 주제로 발표하면 좋을까? 생각하던 중
최근 침착맨과 콜라보레이션으로 ONE 체크카드가 출시되었습니다.
이 체크카드를 홍보할 수 있는 Shorts를 AI로 자동으로 생성하는 내용을 발표하면 재밌겠다 생각이 되어
세미나 준비를 진행하였고 재밌다는 평가가 있어 블로그를 통해 내용을 소개하고자 합니다.

들어가며
1~2년 전까지만 해도 텍스트를 처리해 주는 AI모델들 LLM(Claude, OpenAI, LLaMA 등)이 화두였는데요.
최근에는 이미지 생성은 물론이고 오디오, 비디오까지 생성해 줄 수 있는 다양한 AI모델들이 공개 & 개발되었고
여러 회사에서 API 서비스를 제공함으로써 다양한 AI 서비스들이 출시되고 있습니다.
AI 프로젝트를 떠올리면 생각나는 프로젝트의 형태는 아래 두 가지 정도인데요.
1. 프롬프트(Text) 형태의 Input을 받아서 RAG (Embedding model or VectorDB or 웹 검색)를 활용하는 챗봇과 같은 형태
2. 프롬프트(Text) 또는 이미지를 Input을 받아서 이미지를 생성하는 형태
이번에 소개드릴 AI Shorts 만들기는 LLM, 비디오 생성 모델, TTS 총 3개의 모델을 조합하여 AI 프로젝트를 진행하는 방법에 대해서 소개해드리고자 합니다.

영상 제작 과정
우리가 보는 Shorts형태의 영상을 살펴보면 소리(오디오, 나레이션), 영상(Video), 자막(Text) 3가지로 구성이 되어있습니다.
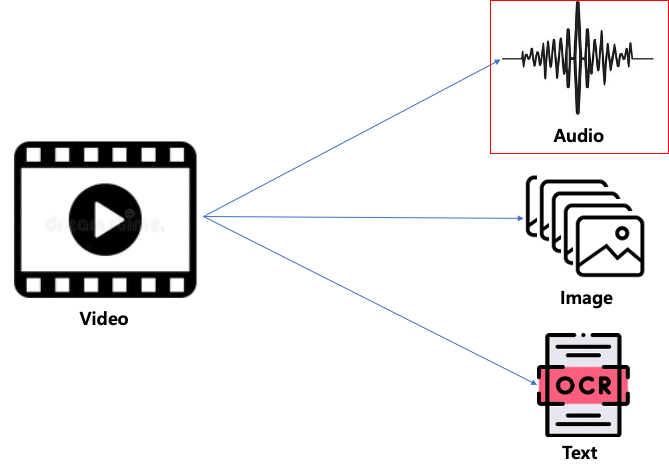
위에서 언급한 대로 소리, 영상, 자막을 차례차례 생성해서 3개를 조합하게 되면 Shorts가 만들어지게 됩니다.

AI Shorts 만들기
AI Shorts는 침착맨과 유사한 모델이 을지로를 걸어가는 힙(?)한 분위기의 영상을 만들 예정입니다.
1. 이미지 생성
우선 침착맨을 떠올릴 수 있도록 실사 모델 이미지를 만듭니다.
gpt-image-1 모델을 사용해 ONE 체크카드를 참조 이미지로 넣어 내가 만들고자 하는 이미지의 상세 내용을 담아 신규 이미지를 생성합니다.
# step1. 이미지 생성
prompt = """
케이뱅크에서 새로출시한 체크 카드 발급 유도를 위한 마케팅을 위한 9초짜리 쇼츠를 만드려고 해.
이 쇼츠는 서울 을지로 4가를 배경으로 20대 학생이 모델로 나오는 쇼츠로 기획하고 있어.
길을 걷고 있는 모습의 이미지였으면 좋겠어.
"""
images = ["data/card.png"]
imgs, prompt = img_generator.edit_multiple_images(
prompt = prompt,
images = images,
n = 1,
size = "1024x1024",
background = "opaque",
quality = "auto",
model = "gpt-image-1",
timer_interval = 2
)

2. 비디오 생성
LumaAI의 ray-2 api를 이용하여 비디오를 생성합니다.
이 모델의 경우 한글 프롬프트를 지원하지 않기 때문에 gpt-4o 모델을 이용해서 만들어진 실사 이미지에 모션을 설명해주는 내용(프롬프트)을 영어로 생성하고 이 프롬프트와 위에서 만들어진 이미지로 비디오를 생성합니다.
정리
2-1. 1번에서 생성된 이미지에 대한 비디오 프롬프트 생성 (gpt-4o)
2-2. 생성된 프롬프트와 이미지로 9초 비디오 생성 (ray-2)
# step2. 비디오 생성을 위한 프롬프트 작성
from openai import OpenAI
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
luma_video_prompt = """
You are a cinematic scene describer trained to generate short, vivid prompts for Luma Labs Dream Machine.
Given a visual scene, generate a short cinematic prompt (15–35 words) that describes the subject, action, mood, lighting, and camera movement or angle.
Examples:
1. "A massive orb of water floating in a backlit forest"
2. "An explosion with camera shake"
3. "Raindrops in extreme slow motion"
4. "A snow leopard crouched on a rocky ledge, staring directly at camera, snowflakes falling around it"
5. "A detective in a dark trench coat and hat, holding a lantern, walks carefully down a narrow cobblestone alley, mist curling around his feet"
6. "At sunrise, place the camera at ground level, looking up at a solitary warrior standing on a rugged cliff edge, wind pulling at his cloak"
7. "A tiny chihuahua dressed in post-apocalyptic leathers with a WW2 bomber cap and goggles sits proudly on a makeshift throne"
8. "A cellist alone on stage under a single spotlight, camera slowly circling her as she begins to play"
9. "A gorilla surfing on a wave, water splashing dramatically as it leans into the motion"
Now, based on the input image or concept, generate a similarly styled prompt that is cinematic, physical, and emotionally engaging.
Output only the prompt text.
"""
client = OpenAI(api_key=OPENAI_KEY)
# Getting the Base64 string
base64_image = encode_image(output_path)
response = client.responses.create(
model="gpt-4o",
input=[
{
"role": "user",
"content": [
{ "type": "input_text", "text": luma_video_prompt },
{
"type": "input_image",
"image_url": f"data:image/jpeg;base64,{base64_image}",
},
],
}
],
)
print(response.output_text)
# step3. 비디오 생성
video_prompt = response.output_text
keyframes = [output_path]
video_bytes, prompt = luma_generator.generate_video(video_prompt,
keyframes=keyframes,
loop=True,
model="ray-2",
aspect_ratio="9:16",
resolution="720p",
duration="9s",
)
3. 자막 생성
Shorts의 자막(컨텐츠)도 AI를 통해 만듭니다.
내가 만들려고 하는 내용과 One체크카드에 대한 설명을 프롬프트에 전달하여 gpt-4o를 이용하여 9초 영상에 담길 8줄의 자막을 생성합니다. (1초당 1줄씩)
결과 : ['새로운 카드', '원 체크카드', '혜택 선택', '더 큰 캐시백', '편의점, 카페', '매일매일 혜택', '이제 시작해', '케이뱅크와 함께']
# step4. 자막 생성
# Path to your image
image_path = "sample.png"
# Getting the Base64 string
base64_image = encode_image(image_path)
prompt = """
케이뱅크에서 새로나온 One체크카드를 소개하는 쇼츠 영상 자막 8줄 만들어줘
TTS로 말했을 때 총 발화 시간이 8.5초 이내여야 해.
각 줄은 되도록 8자 이내, 짧고 리듬감 있게 만들어줘.
말했을 때 자연스럽고 부드러운 흐름이 되도록 해줘.
번호나 따옴표 없이, 줄바꿈으로만 구분해줘.
쇼츠로 만드려고하는 이미지 썸네일도 같이 첨부 해줄게
반드시 추가 설명 없이 자막 8줄만 만들어줘.
카드 혜택 :
✅ 케이뱅크 ONE 체크카드 (연회비·실적 조건 없음)
매월 원하는 캐시백 혜택을 자유롭게 선택할 수 있는 체크카드입니다.
1.여기서 더 캐시백
편의점, 카페, 배달앱, OTT, 영화 업종에서 7% 캐시백
건당 1만 원 이상 결제 시 적용 (일 1천 원, 월 2만5천 원 한도)
2. 모두 다 캐시백
오프라인 업종 0.7%, 온라인 쇼핑 1.2% 캐시백
실적 조건, 한도 없이 자동 적용
3. 369 캐시백
월 결제 횟수가 3회, 6회, 9회일 때 각 1,000원 캐시백
건당 5천 원 이상 결제 시 적용 (스탬프 형태로 확인 가능)
4. 대중교통 추가 캐시백
카드로 대중교통 월 5만 원 이상 이용 시 3,000원 추가 캐시백
"""
response = client.responses.create(
model="gpt-4o",
input=[
{
"role": "user",
"content": [
{ "type": "input_text", "text": prompt },
{
"type": "input_image",
"image_url": f"data:image/jpeg;base64,{base64_image}",
},
],
}
],
)
print(response.output_text)
# ['새로운 카드', '원 체크카드', '혜택 선택', '더 큰 캐시백', '편의점, 카페', '매일매일 혜택', '이제 시작해', '케이뱅크와 함께']
4. 오디오 생성
만들어진 자막을 OpenAI의 TTS(Text to Speech) 모델을 이용하여 오디오를 생성합니다.
자막과 오디오의 싱크를 맞추기 위해서 8개의 문장을 한 번에 TTS로 오디오 파일을 만드는 것이 아니라 1 문장당 1초씩 될 수 있게
8개의 오디오 파일을 만들고 이후에 합쳐줍니다.
# step5. tts(text to speach)
# https://platform.openai.com/docs/guides/text-to-speech
import openai
import asyncio
import nest_asyncio
import asyncio
# jupyter notebook에서 아래 코드 실행
nest_asyncio.apply()
# 비동기 클라이언트 인스턴스 생성
async_client = openai.AsyncOpenAI(api_key=OPENAI_KEY)
# 개별 TTS 요청 (async)
async def generate_tts(client, text, index, voice="shimmer", model="tts-1"):
filename = f"line_{index+1}.mp3"
try:
response = await async_client.audio.speech.create(
model=model,
voice=voice,
input=text,
)
with open(filename, "wb") as f:
f.write(response.content)
print(f"✅ 생성 완료: {filename}")
return filename
except Exception as e:
print(f"❌ TTS 오류 (line {index+1}): {e}")
return None
# 여러 줄 비동기 처리
async def generate_all_tts(lines, voice="shimmer"):
tasks = [
generate_tts(client, line, idx, voice=voice)
for idx, line in enumerate(lines)
]
return await asyncio.gather(*tasks)
tts_files = asyncio.run(generate_all_tts(lines))
# step6. 오디오 파일 병합
import subprocess
#3. 오디오 파일 연결을 위한 concat list 파일 생성 ###
with open("concat_list.txt", "w") as f:
for filename in tts_files:
f.write(f"file '{filename}'\n")
# 4. TTS 오디오 병합 ###
print("🎵 TTS 오디오 병합 중...")
subprocess.run([
"ffmpeg", "-y", "-f", "concat", "-safe", "0",
"-i", "concat_list.txt", "-c", "copy", "combined.mp3"
], check=True)
5. 자막 파일 생성
위에서 만들어진 문장을 비디오에 합치기 위한 *. srt파일의 형태로 만듭니다.
# step7. 자막 생성 (정확히 1초 간격)
print("📝 SRT 자막 생성 중...")
with open("output.srt", "w", encoding="utf-8") as f:
for i, line in enumerate(lines):
start_time = f"00:00:0{i}.000"
end_time = f"00:00:0{i+1}.000"
f.write(f"{i+1}\n{start_time} --> {end_time}\n{line}\n\n")
6. 영상 + 오디오 + 자막 합성
# step8. 영상과 오디오, 자막 결합
video_input = "shorts.mp4"
output_video = "final_output.mp4"
subprocess.run([
"ffmpeg", "-y",
"-i", video_input,
"-i", "combined.mp3",
"-vf", "subtitles=output.srt",
"-c:v", "libx264", "-c:a", "aac",
output_video
], check=True)
print(f"✅ 완료: {output_video}")
결과
마치며
LLM 모델, 이미지 모델, 오디오 모델 (STT, TTS) 등 여러 개의 모델을 조합하면 다양한 AI 프로젝트가 만들어질 수 있습니다.
또 다른 예로, STT(Speech To Text)모델과 영상을 이용한다면 영상에서 오디오를 추출하여 대본으로 만들고(Whisper) llm모델을 이용하여 중요하다고 생각하는 부분을 찾아 20~30초 내외로 자르면 핫 클립영상이 만들어집니다.
여러 모델들이 API형태로 쉽게 사용이 가능하고 프로그래밍 또한 ChatGPT의 도움을 받는다면 아이디어만 있으면 프로젝트를 손쉽게 만들 수 있는 세상이 된 것 같습니다.
Edit에서는 AI와 관련된 내용 외에도 점심시간에 동아리 분들끼리 삼삼오오 모여서
동아리 지원비로 먹을 수 있는 맛있는 음식과 함께 다양하고 재미있는 세미나(IT, 디자인 등)를 진행하고 있습니다.
만약 케이뱅크에 오시게 된다면 Edit 동아리 많은 관심 부탁드리겠습니다!
감사합니다.
https://github.com/GreenD93/shorts
GitHub - GreenD93/shorts
Contribute to GreenD93/shorts development by creating an account on GitHub.
github.com
'Tech' 카테고리의 다른 글
| 차세대 은행은 어떤 모습 일까? - 1편 (Agentic AI) (0) | 2025.09.07 |
|---|---|
| Figma Config 2025 참관기: 디자인 도구에서 제품 협업 플랫폼으로 (0) | 2025.07.21 |
| KPick (이미지 생성기), AI 아이콘에 생명을 불어넣다 3편 (0) | 2025.05.28 |
| AWS Backup 서비스를 통한 EC2 백업 체계 개선 (0) | 2025.05.27 |
| 프롬프팅 대신 프로그래밍 - DSPy를 활용한 프롬프트 자동 최적화 (4) | 2025.05.02 |