안녕하세요. 케이뱅크 DataBiz팀에서 데이터 사이언티스트로 일하고 있는 조용걸입니다.
이 글에서는 ChatGPT와 Streamlit을 활용해 행내에서 진행했었던 PoC에 대해서 소개해 드리고자 합니다.

ChatGPT를 활용한 어플리케이션
올 해에는 ChatGPT효과(?)로 관련 종사자뿐만 아니라 일반인들도 LLM, Foundation Model, ChatGPT의 문제점, 활용 사례 등을 뉴스나 다른 매체를 통해 심심치 않게 해당 내용을 접할 수 있었습니다. 그리고 업권과 분야를 가리지 않고 ChatGPT를 접목할 수 있는 방법과 사례에 대한 내용들이 테크 세미나에 단골 주제로 화두가 되었던 해였습니다. 이러한 분위기 덕택에 자연스레 행 내에서도 ChatGPT를 활용해 업무 생산성 또는 고객 경험을 향상할 수 있는 방안에 대한 논의를 하게 되었습니다. PoC를 진행하면서 고민했던 점과 내용에 대해 소개드리고자 합니다.
ChatGPT를 은행에 적용했을 때 망분리/리소스/레이턴시와 같은 문제점도 물론 존재하지만 실사용 관점에서 생성된 결과를 그대로 사용할 적에 아래 문제와 마주하게됩니다.
- 정보의 정확성과 최신성
- Brand 일관성
정보의 정확성과 최신성
은행 상품들은 외부 환경에 영향을 많이 받습니다. 특히, 작년과 올해 금리 정책에 따라 은행의 여수신(대출, 예적금 등) 상품들의 금리가 잦게 변하였습니다. 만약, 최신 정보가 업데이트되지 않은 상태에서 모델이 잘못된 정보를 제공한다면 고객이 피해를 볼 수 있고 이는 고객 경험으로 이어져 앱 더 나아가서 신뢰성이 중요한 은행에 치명적일 수 있습니다.
Brand 일관성
은행에서 마케팅을 진행할 때 해당 콘텐츠에 대해 준법감시팀에서의 해당 내용의 적절성에 대한 검토를 진행합니다. 그리고 Brand팀에서는 해당 콘텐츠들이 고객에게 전달되었을 때의 경험을 케이뱅크가 추구하는 Brand와 일치하는지 추가 검수 하여 교정을 하고 최종적으로 교정된 컨텐츠들이 고객에게 노출되게 됩니다. 따라서, ChatGPT로 생성된 문구가 내용의 오류 없이 잘 만들어졌다 하더라도 행이 추구하는 Brand성을 해치지 않으면서 잘 만들어져야 하는 전제가 하나 생기게 됩니다.
RAG(Retrieval Augmented Generation)
RAG는 모델 외부에서 정보를 가져와 ChatGPT와 같은 생성형 AI모델의 정확성과 신뢰성을 향상시키는 기법입니다. Data의 정확성과 최신성을 반영하기 위해 모델을 zero-base부터 재학습하거나 fine-tuning을 하는 것이 아닌, 외부 정보만을 업데이트함으로써 이전 방법들보다 저비용으로 많은 리소스 투입 없이 정보의 정확성과 최신성 문제에 대응할 수 있습니다.
제공하는 외부 정보에 기반하여 답변을 생성하기 때문에 적절한 프롬프팅(prompting)과 함께 사용한다면 위에서 언급했던 정보의 정확성과 최신성 그리고 답변의 일관성 문제에 대해서 대응을 가능하게 합니다.
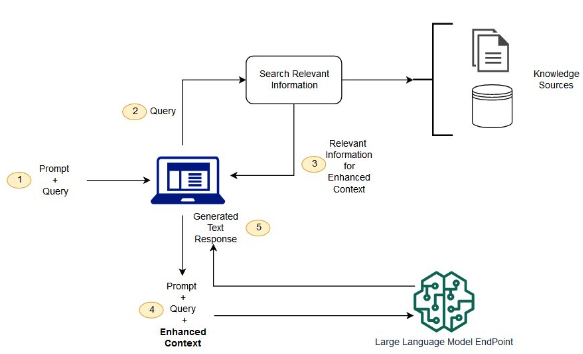
애플리케이션
애플리케이션은 Streamlit으로 데모 페이지를 구성하였으며 OpenAI의 chat completions API를 사용해서 개발하였습니다. Q&A 챗봇의 경우에 사용자 질의와 자주 하는 문의 질문들과의 Vector Embedding과 유사도 검색을 위해 hugging face의 Sentence Transformer(jhgan/ko-sroberta-multitask) 모델과 Faiss를 사용해 아키텍처를 구성하였습니다.
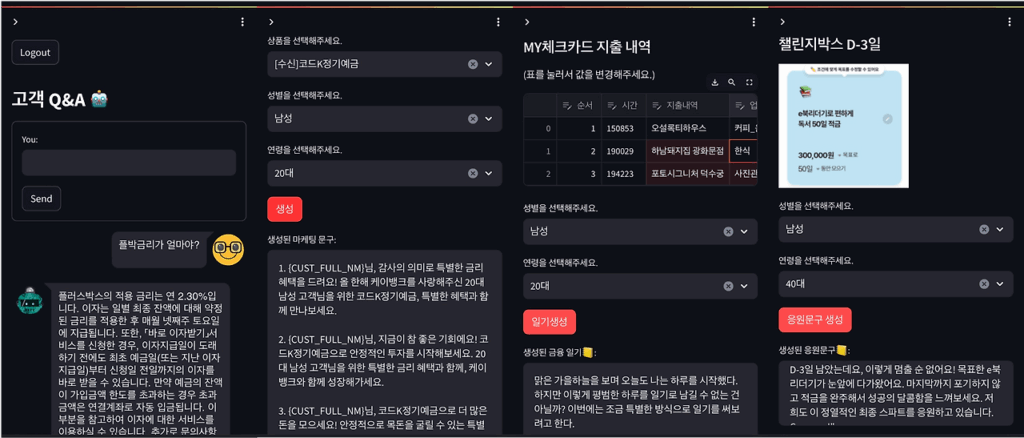
- Q&A 챗봇
- 마케팅 문구 만들기
- 나의 소비 일기
- 예/적금 완주 응원문구
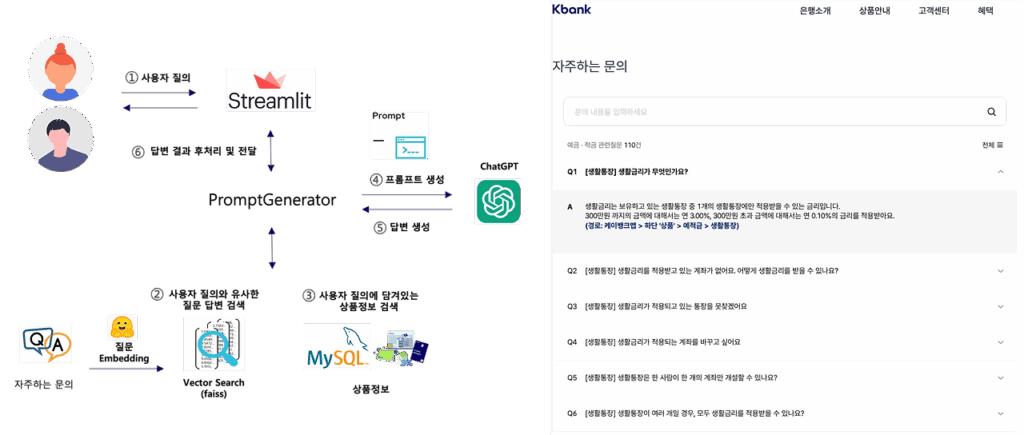
Q&A와 같은 챗봇 영역은 LLM을 활용할 수 있는 가장 매력적인 영역입니다. 같은 내용을 물어보는 질문이라도 사용자 질의가 다양한 형태로 표현될 수 있기 때문에 시나리오 베이스로 챗봇을 구성하게 되면 고려해야 할 요소가 많아집니다(동의어, 준말, 질의 순서 등). 이를 충분한 Dataset으로 학습된 LM(Language Model)을 이용해 문장 Vector를 사용하면 문장의 문맥적 의미(의도) 뿐만 아니라 동음이의어와 같은 인식 문제도 대응할 수 있습니다.
- 고객센터 자주 하는 문의 질문들에 대해서 Sentence Embedding(jhgan/ko-sroberta-multitask) 진행 후 VectorSearch를 위해 Faiss에 저장
- 상품정보(금리, 상품설명 등) DB에 저장
- 사용자 질의{instruction}가 들어왔을 때 Sentence Embedding 후 Faiss를 통해 가장 유사한 질문에 대한 답변{docs}을 검색 – RAG
- 사용자 질의에 상품 이름이 있을 경우 DB에서 상품 정보{prd_info}를 검색 – RAG
- 3번, 4번에서 검색한 결과를 바탕으로 프롬프트를 생성해 사용자 질의에 답변 – ChatGPT
PROMPT_DICT = {
“CHAT_BOT” : (
“서비스 센터 직원처럼 응답해주세요.\n\n”
“응답할 때, 모든 문서를 참고하세요.\n”
“응답할 때, 상품정보를 참고하세요.\n”
“응답할 때, 금리와 관련이 있는 질문은 반드시 금리도 함께 알려주세요.\n”
“응답할 때, Instruction에 대한 내용을 짧게 정리해주세요.\n\n”
“### 문서 :\n{docs}\n\n”
“### 상품정보 :\n{prd_info}\n\n”
“### Instruction(명령어):\n{instruction}\n\n### Response(응답):”
)
}
마케팅 문구 만들기
케이뱅크 앱에서는 하루에도 150개가 넘는 마케팅(홈 상단, 반팝업) 배너가 운영되고 있습니다. 개인의 선호를 추정하여 선호 상품에 대한 마케팅 배너를 띄어주는 것도 중요하지만, 이에 못지않게 배너에 사용되는 이미지와 문구가 클릭에 상당한 영향을 미치게 됩니다. 고객의 선호 상품이더라도 같은 문구가 매일 노출된다면 고객의 관심을 끌지 못하고 피로를 누적시키기 때문이죠.
마케팅 문구는 ① 담당 BM 작성 → ② 준법 심의 (문구가 적절한지) → ③브랜드팀 검수 (Brand 일관성) 3개의 프로세스를 거쳐 비로소 앱에 사용가능한 형태로 만들어지게 됩니다. 행 내에는 이 프로세스를 거친 고품질의 문구로 만들어진 마케팅 캠페인들과 그 결과로써의 고객 반응 정보가 축적되어 있습니다. 이 정보들을 활용하여 담당 BM에게 고 반응의 마케팅 문구를 고려한 초안을 제공한다면 업무 생산성 향상을 기대할 수 있습니다.
- 마케팅 문구를 생성하고자 하는 상품 선택
- 타겟팅 대상의 사용자 데모 정보 (성별, 연령 직업) 선택
- 프롬프트 생성 – generate_prompt(prod_nm, geng, ageg, jobseg)
a. 상품 정보 검색 – _search_prod_infos(prod_nm)
b. 타겟팅 하고자 하는 상품의 타겟팅 고객 데모 반응 Best5(CTR 기준) 문구 검색 – _search_best_mkt_phrases(prod_nm, geng, ageg, jobseg) - 프롬프트 바탕으로 결과 생성 및 후처리 – generate_mkt_phrase(prod_nm, name, prompt)
a. ChatGPT API를 이용하여 마케팅 문구 생성 – _generate_chat_completion(prompt)
b. 결과 후처리 – preprocess_response(response, name)
import openai
import re
from src.db_utils import *
from src.prompt import *
from config.settings import *
openai.api_key = OPENAI_KEY
class MKTPhraseGenerator:
def __init__(self):
self.prompt = PROMPT_DICT[“MKT_PHRASE_PRMPT”]
self.basic_prod_dic = {
‘aptloan’: “아파트 담보대출”,
‘codek_freeaccount’: “자유적금”,
‘coin_info’: “가상자산(비트코인) 시세정보”,
‘hiteenpromotion’: “중/고등학생 체크카드”,
‘homelearn_event’: “초등학생 학습지”,
‘togetheraccount’: “모임통장”
}
self.error_template = {
‘aptloan’: {‘text1’: ‘큰 돈 새는 주담대 이자 이제는 이자도 절약해요 부자 솔루션’, ‘text2’: ‘- 절약 비교해보면 케뱅 아파트담보대출’},
‘codek_freeaccount’: {‘text1’: ‘단순하고 쉬운게 좋다면? ‘, ‘text2’: ‘코드K 자유적금이 딱이에요 복잡한 우대조건 필요 없어요’},
‘coin_info’: {‘text1’: ‘비트코인 시세 조회 어디서 하세요?’, ‘text2’: ‘여기서도 간편하게 조회가 가능해요!’},
‘hiteenpromotion’: {‘text1’: ‘우리 아이 버스•지하철 교통비 500원씩 싸게 타는 방법이 있어요’, ‘text2’: ‘Hi teen 자세히 알아보기’},
‘homelearn_event’: {‘text1’: ‘우리 아이 성적에 고민이 많으신 부모님들!’, ‘text2’: ‘전교 1등 노하우 알려드릴게요!’},
‘togetheraccount’: {‘text1’: ‘같이 모으는 돈에도’, ‘text2’: ‘최고 연 10%(세전) 이자 받기’}
}
pass
def generate_mkt_phrase(self, prod_nm, name, prompt):
“””
Input:
prod_nm: str
name: str
prompt: str
Return:
text1: str ex) 큰 돈 새는 주담대 이자 이제는 이자도 절약해요 부자 솔루션
text2: str ex) – 절약 비교해보면 케뱅 아파트담보대출
“””
response = self._generate_chat_completion(prompt)
print(response)
try:
text1, text2 = self.preprocess_response(response, name)
except:
# error handle
error_handle_texts = self.error_template[prod_nm]
text1, text2 = error_handle_texts[‘text1’], error_handle_texts[‘text2’]
return text1, text2
def preprocess_response(self, response, name):
“””
Input:
response: str
Return:
text1: str
text2: str
“””
def _preprocess_pipeline(response):
pipe_cnt = response.split(‘|’)
if len(pipe_cnt) == 2:
text1, text2 = response.split(“|”)
return text1, text2
else:
texts = response.split(‘|’)
text1 = texts[0]
text2 = ” “.join(texts[1:])
return text1, text2
def _preprocess_text(text, name):
# regex
text = re.sub(‘[0-9]위.’, ”, text)
text = re.sub(‘[0-9]위’, ”, text)
# replace
text = text.replace(‘결과:’, ”)
text = text.replace(‘”‘, ”)
text = text.replace(‘\n’, ”)
text = text.replace(‘{CUST_FULL_NM}’, name)
text = text.replace(‘(CUST_FULL_NM)’, name)
text = text.replace(‘[CUST_FULL_NM]’, name)
text = text.replace(‘{고객}’, name)
text = text.replace(‘(고객)’, name)
text = text.replace(‘[고객]’, name)
text = text.replace(‘고객’, name)
text = text.replace(‘(첫 번째 문장)’, “”)
text = text.replace(‘(두 번째 문장)’, “”)
return text
text1, text2 = _preprocess_pipeline(response)
text1, text2 = _preprocess_text(text1, name), _preprocess_text(text2, name)
text1, text2 = text1.strip(), text2.strip()
return text1, text2
def _generate_chat_completion(self, prompt):
response = openai.ChatCompletion.create(
model=”gpt-3.5-turbo”,
messages=[
{
“role”: “user”,
“content”: prompt
}
]
)
response = response[“choices”][0][“message”][“content”]
return response
def _get_basic_prod(self, prod_nm):
return self.basic_prod_dic[prod_nm]
def generate_prompt(self, prod_nm, geng, ageg, jobseg):
basic_prod_nm = self._get_basic_prod(prod_nm)
prod_infos, _ = self._search_prod_infos(prod_nm)
prod_info = prod_infos[‘prod_info’]
prod_promotion_info = prod_infos[‘prod_promotion_info’]
prod_ir = prod_infos[‘prod_ir’]
best_mkt_phrases, _ = self._search_best_mkt_phrases(prod_nm, geng, ageg, jobseg)
prompt = self.prompt.format(
basic_prod_nm=basic_prod_nm,
best_mkt_phrases=best_mkt_phrases,
prod_info=prod_info,
prod_promotion_info=prod_promotion_info,
prod_ir=prod_ir,
ageg=ageg,
geng=geng,
jobseg=jobseg
)
return prompt
def _search_prod_infos(self, prod_nm):
“””
Input:
prod_nm: str ex) ‘aptloan’
Return:
best_mkt_phrases: dict
“””
db = get_db_connection(host=SQL_HOST, user=SQL_USERNAME, passwd=SQL_PASSWD, db=SQL_SCHEMA_NAME)
try:
with db.cursor() as curs:
curs.execute(‘SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED’)
db.commit()
sql = f”””
SELECT prod_nm, prod_info, prod_promotion_info, prod_ir
FROM prd_info
WHERE
prod_nm = ‘{prod_nm}’
“””
print(sql)
curs.execute(sql)
rows = curs.fetchall()
row = rows[0]
prod_nm = row[0]
prod_info = row[1].replace(‘\\n’,’\n’)
prod_promotion_info = row[2].replace(‘\\n’,’\n’)
prod_ir = row[3].replace(‘\\n’,’\n’)
prod_infos = {
‘prod_nm’ : prod_nm,
‘prod_info’: prod_info,
‘prod_promotion_info’: prod_promotion_info,
‘prod_ir’: prod_ir
}
return prod_infos, True
except:
prod_infos = {
‘prod_nm’ : ”,
‘prod_info’: ”,
‘prod_promotion_info’: ”,
‘prod_ir’: ”
}
return prod_infos, False
def _search_best_mkt_phrases(self, prod_nm, geng, ageg, jobseg):
“””
Input:
prod_nm: str ex) ‘aptloan’
gegng: str ex) ‘여성’
ageg: str ex) ’20대’
jpbseg str ex) ‘전문직’
Return:
best_mkt_phrases: str
“””
db = get_db_connection(host=SQL_HOST, user=SQL_USERNAME, passwd=SQL_PASSWD, db=SQL_SCHEMA_NAME)
try:
with db.cursor() as curs:
curs.execute(‘SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED’)
db.commit()
sql = f”””
SELECT mkt_phrase
FROM mkt_phrase
WHERE
prod_nm = ‘{prod_nm}’
and geng = ‘{geng}’
and ageg = ‘{ageg}’
and jobseg = ‘{jobseg}’
ORDER BY ctr desc
LIMIT 5;
“””
print(sql)
curs.execute(sql)
rows = curs.fetchall()
best_mkt_phrases = “”
for idx, row in enumerate(rows):
mkt_phrase = row[0]
best_mkt_phrases += f”{idx + 1}위. {mkt_phrase}\n”
return best_mkt_phrases, True
except:
best_mkt_phrases = “”
return best_mkt_phrases, False
if __name__ == ‘__main__’:
# user info
user_info = {
‘prod_nm’: ‘aptloan’,
‘name’: ‘kbank’,
‘geng’: ‘여성’,
‘ageg’: ’20대’,
‘jobseg’: ‘전문직’
}
prod_nm = user_info[‘prod_nm’]
name, geng, ageg, jobseg = user_info[‘name’], user_info[‘geng’], user_info[‘ageg’], user_info[‘jobseg’]
# define mkt_phrase_generator
mkt_phrase_generator = MKTPhraseGenerator()
# generate prompt
prompt = mkt_phrase_generator.generate_prompt(prod_nm, geng, ageg, jobseg)
# get openai response
text1, text2 = mkt_phrase_generator.generate_mkt_phrase(prod_nm, name, prompt)
# output
print(text1, text2)
나의 소비 일기
매일 발생하는 소비 지출을 통해 나의 하루를 요약할 수 있습니다. 특히, 특별한 날에 특별한 누군가와 함께 보낸 날의 지출내역들은 일반적인 일상과 다른 하루를 보냈다는 것을 나타냅니다. 시간별 발생된 체크카드 지출 내역을 통해 추억을 남길 수 있는 소비 일기를 생성형 AI로 만들어 고객의 앱 참여를 유도하고 앱 사용 경험을 향상할 수 있습니다.
예/적금 완주 응원문구
케이뱅크의 챌린지박스는 저축 목표와 기간을 정하고 해당 시점까지 목표한 금액을 모을 수 있도록 도와주는 적금 상품입니다. 만기일까지 고객의 챌린지를 달성할 수 있게 D-X별로 다른 응원문구를 생성함으로써 완주를 독려합니다.
한계점 및 보완점
4개의 PoC를 진행하면서 아이디어만 있다면 손쉽게 ChatGPT를 활용해 더 많은 애플리케이션을 만들 수 있겠다고 느꼈습니다. 하지만 이와 반대로 실제 비즈니스에 적용하기 위해 더 필요하다고 생각하는 한계점 및 보완점에 대해서 공유하고자 합니다.
1. 프롬프트 엔지니어링과 예외처리
아래는 마케팅 문구를 만드는 프롬프트입니다. 프롬프트 엔지니어링은 프롬프트 안의 순서(제약조건, 마케팅 대상, 참고 내용, 출력형식)와 내가 풀려고 하는 문제를 어떻게 정의했느냐에 따라서 결과의 품질이 달라집니다. 풀려고 하는 문제를 단계별로 세분화하고 내가 기대하고자 하는 결과를 어떻게 표현할 수 있는가에 대한 고민이 중요한 영역 같습니다. 이후 답변의 품질을 어떻게 측정할 수 있는가? 에 대한 부분도 비즈니스에 적용 시 반드시 고려해야 할 숙제라 생각이 듭니다.
또한, 제약조건과 출력 형식을 프롬프트로 제한하였다 하더라도 원하지 않은 형태의 결과가 생성될 수 있습니다. 따라서, 몇 번의 결과를 보고 판단하는 것이 아닌 여러 번의 시뮬레이션을 통해서 내가 희망하는 결과가 나오게 하는 프롬프트를 찾아야 하고 희망하지 않은 결과가 나왔을 때의 예외처리도 함께 고려해야 합니다.
PROMPT_DICT = {
“MKT_PHRASE_PRMPT” : (
“# 명령문\n”
“당신은 창의성이 뛰어난 마케팅 컨텐츠(문구) 제작 전문가 입니다.\n”
“마케팅 상품은 {basic_prod_nm} 입니다.\n”
“마케팅 대상에게 유용한 상품정보를 제공하고 어플리케이션 사용 몰입도를 높여 마케팅 상품을 가입하고 싶게 만들어야 합니다.\n”
“마케팅 대상에게 상품상세정보들을 참고하여 제약조건과 출력형식을 따르는 마케팅 문구를 만들어주세요.\n\n”
“———————\n\n”
“# 제약조건\n”
“마케팅 컨텐츠를 만들 때 상품정보, 상품혜택, 기타정보를 반드시 참고하여 문구를 만들어주세요.\n”
“마케팅 컨텐츠에는 마케팅 대상의 성별, 연령, 직업적 특징이 반드시 나타나게 만들어주세요.\n”
“과거 가장 반응이 좋았던 마케팅 문구들도 참고하여 문구를 만들어야합니다.\n”
“마지막으로, 마케팅 문구에 사용되는 어휘는 명료하고 마케팅 대상에게 권유 하듯이 만들어주세요.\n\n”
“# 마케팅 대상\n”
“- 성별: {geng}\n”
“- 연령: {ageg}\n”
“- 직업: {jobseg}\n\n”
“# 참고 내용\n”
“## 과거 가장 반응이 좋았던 마케팅 문구\n”
“{best_mkt_phrases}\n”
“## 상품상세정보\n”
“### 상품정보\n”
“{prod_info}\n\n”
“### 상품혜택\n”
“{prod_promotion_info}\n\n”
“### 기타정보\n”
“{prod_ir}\n\n”
“# 출력 형식\n”
“다음의 형식을 따라 답변하세요.\n”
“띄어쓰기와 맞춤법을 지켜주세요.\n”
“생성된 마케팅 문구는 반드시 2개의 문장으로 만들어져야 합니다.\n”
“생성된 각 문장의 최대 길이는 20글자로 제한합니다.\n\n\n”
“결과: (첫 번째 문장) | (두 번째 문장)”
)
}
2. 신뢰성(Reliability)
ChatGPT API는 응답 시간(Latency)과 결과에 대한 신뢰성(Reliability) 문제가 존재합니다. 여러 번 시뮬레이션을 거쳐 평균 시간을 잡았다 하더라도 평균 시간을 훨씬 상회해서 응답이 오기도 하며 이전에 생성했던 같은 프롬프트에 대해서 간혹 답변을 생성하지 못하는 경우가 발생했습니다. 따라서, 이러한 문제를 인지하고 응답시간이 지연 또는 생성을 해주지 못했을 때를 염두에 두고 애플리케이션을 운영해야 합니다.
이 외에도 금융권 도메인 특징상 비즈니스에 적용할 경우 망분리 이슈가 존재하기 때문에 업무망에서 ChatGPT와 같은 기능을 사용할 수 있는지 또는 온프레미스에 한국어를 잘 이해하는 모델을 들여올 수 있는지 등 다방면으로 다양한 부서의 협조 및 검토가 필요합니다.
맺음말
ChatGPT 등장 이후 LLM을 적용한 비즈니스 및 어플리케이션 사례들이 다양한 분야에서 소개되고 있습니다. 더 나아가서 오픈 소스 라이브러리인 LangChain과 Streamlit과 같은 패키지들은 빠르고 간편하게 LLM 어플리케이션 개발을 가능하게 하여 이러한 현상을 더 가속화하고 있습니다. 이러한 흐름 속에 금융 도메인에서도 생성형 AI의 활용은 당연한 수순의 방안일 것입니다. 행 내 그리고 DataBiz팀에서도 업무 생산성과 고객 경험 향상을 위해 관련 논의가 되고 있는 만큼 근 시일 내에 생성형 AI를 적용한 차별화된 서비스가 개발되기를 기대합니다.
긴 글 읽어주셔서 감사합니다.
[금융 속 AI ①] 은행은 왜 AI에 투자할까?
[인턴십] 2기 인턴 워크샵 하이라이트
[케미스토리] 개발자가 ‘자율’적으로 일하는 법